近日,国际计算机图形与交互技术顶会SIGGRAPH Asia 2024公布论文接收结果:网易伏羲最新研究成果《FreeAvatar: Robust 3D Facial Animation Transfer by Learning an Expression Foundation Model》成功入选。今年12月,SIGGRAPH Asia 2024大会将在日本东京举行,届时网易伏羲实验室视觉计算团队成员将在大会现场亲述报告,与来自世界各地的计算机图形学专家和爱好者进行深入交流。

ACM SIGGRAPH年会由美国计算机学会(ACM)主办的计算机图形学顶级年度会议,每年在全球范围内举行两次,包括夏季在北美举办的SIGGRAPH以及冬季在亚洲举办的SIGGRAPH Asia。该会议是迄今为止世界上影响最广、规模最大,也是最权威的集科学、技术、艺术、商业于一身的图形学技术展示和学术会议。
此次网易伏羲的相关研究成果成功入选并受邀分享,彰显了其在表情理解与生成领域长期的创新努力,同时也为这些技术的应用与进步开辟了新的方向。该项研究成果首先在游戏中进行了落地实验,目前已成功应用于《逆水寒》手游中,合作推出的独具特色的“剧组模式”玩法自3月上线以来受到用户广泛好评,玩家能在游戏中一键完成AI选角、取景和拍摄,打字就能生成影视大片。
此外,在表情捕捉技术方面,该技术相较于传统的面部捕捉技术展现出了明显的优势。传统方法通常需要先进行面部捕捉,然后由美术人员进行精修;而采用我们的方法,算法可以直接输出高质量的结果,只需少量精修即可达到甚至超越传统方法的效果,不仅大幅减少了面部捕捉后处理的人力需求,显著提升了工作效率,同时也确保了最终输出的高质量。
在推动实践应用的同时,网易伏羲也在不断推进技术的迭代更新。论文中的核心技术——表情理解能力,已在ICCV 2021、CVPR 2022、CVPR 2023、CVPR 2024以及ECCV 2024国际表情识别挑战赛中连续五年夺冠,在CVPR 2024和ECCV 2024中更是包揽了全部赛道的冠军。未来,网易伏羲将进一步深入探索人脸表情的细粒度理解和生成,为行业带来更多创新成果。
以下为本次入选论文概要:
《FreeAvatar: Robust 3D Facial Animation Transfer by Learning an Expression Foundation Model》
基于表情基础大模型实现鲁棒的3D面部动画迁移

关键词:表情表征,面部动画迁移,半监督学习涉及领域:表情理解,面部动画捕捉,人脸重建
论文链接:http://arxiv.org/abs/2409.13180
开源链接:https://github.com/FuxiVirtualHuman/free_avatar
3D面部动画迁移旨在捕捉人类面部的表情和动作,为数字化身创建逼真的面部动画。相关技术在多个领域展现出广阔的应用前景,尤其是在数字人、CG游戏、虚拟现实(VR)和增强现实(AR)等领域。它不仅可以增强角色动画的真实性和细节,使游戏世界更加生动,还能提供更加沉浸式的体验,帮助用户在虚拟环境中实现更自然的互动和交流。在工业界,面部动作捕捉系统,如Faceware和ARKit已经被广泛应用于实际生产,相比手动创建的动画,这些系统能够呈现更为精细的面部表情。随着计算机视觉技术的发展,视频驱动的面部动画迁移方法因其便捷性和低成本而受到越来越多的关注。然而,在实现自然和准确的表情迁移的同时,保证面部表情的一致性仍是一个待解决的挑战。
现有的方法通常同时采用面部几何先验和表情特征,以保持输入人脸和目标脸之间表情的语义一致性。然而,这些方法往往难以驱动目标角色生成高保真表情。首先,基于面部标记点的几何约束难以有效捕捉表达的细微变化,例如轻微皱眉和嘴唇压缩。此外,现有方法所采用的表情特征通常基于有限类别的离散情感分类任务进行训练,无法捕捉到细微的情感差异。
在此背景下,网易伏羲开创性地提出了一种仅依赖表情表征的高精度面部动画迁移方法——FreeAvatar,不仅能够在不牺牲精度的情况下大幅提升动画生成的速度,还能够更好地捕捉到细微的情感差异,使得生成的面部动画更加自然流畅。
该方法首先通过学习一个表情基础大模型(Expression Foundation Model),构建了一个细粒度且表征能力强大的隐空间。在这个空间中,具有相似表情的面部图像会聚集在一起,而不同表情的图像则相互远离。接着,我们提出了一种高效的表情驱动多角色动画器(Expression-driven Multi-avatar Animator),能够从提取的表情表征中自适应地生成多个目标角色的面部动画。这一技术突破将大幅降低动画制作的成本与门槛,同时有效提升角色表情的细腻程度和真实感,为多个行业领域提供了创新的解决方案。
该方法的具体亮点和突破如下:
算法创新:我们开发的表情基础大模型旨在构建一个通用的、细粒度且连续的潜在空间,该空间能够适应多种风格的面部图像,包括风格化的人物角色。借助这一模型,FreeAvatar 在进行面部动画迁移时能够保持高度的表情一致性。鲁棒性强:该方案不仅适用于各种背景、光照条件以及不同视角下的面部图像,而且我们还专门针对非真人面部进行了数据和算法优化,确保了其在处理动漫角色或卡通人物时同样具备优秀的泛化能力。降低成本与使用门槛:只需输入一张RGB图像,就能生成相应虚拟角色的面部动画,极大地扩展了应用范围的同时,显著降低了使用成本和技术门槛。
为了展示这一方法的有效性,以下是一系列演示案例,包括与现有面部捕捉设备的比较,与单目人脸重建方法的比较以及结合人脸重建技术完成特定角色的面部动画迁移。这些测试结果不仅凸显了该面部动画迁移算法在处理多样化的面部表情时所具备的高保真度,同时也证明了其在各种复杂环境条件下,甚至是应用于风格化的动漫角色时,依然保持着出色的泛化能力。这一系列的测试验证了该算法作为面部动画制作领域的一种低成本、低门槛、高效解决方案的潜力。

与Faceware面部捕捉设备的效果对比

与MataHuman Animator面部捕捉设备的效果对比
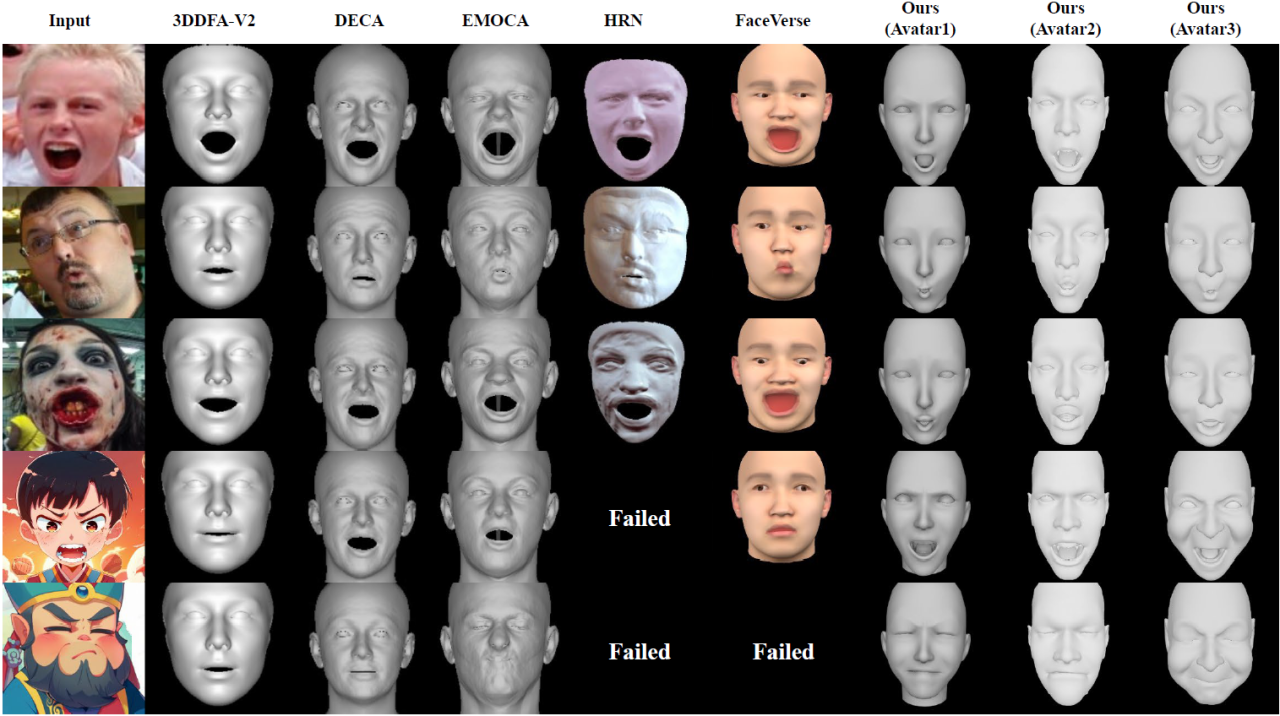
与最新单目人脸重建方案的效果对比

结合人脸重建技术生成特定演员的3D面部动画
(输入素材来源于网络,如有侵权请联系我们)
此次入选SIGGRAPH Asia 2024,标志着网易伏羲在表情理解与生成领域的前沿探索得到了国际认可。未来,随着技术的不断进步,网易伏羲将继续深化对面部表情细粒度理解和生成的研究,推动相关技术迈向更高层次,为行业带来更多的创新成果,助力创造更加丰富和真实的虚拟体验。我们期待,在不久的将来,无论是虚拟的游戏世界还是现实的应用场景,都能在网易伏羲表情理解与生成技术的推动下展现出更加细腻的情感表达,共同开启一个全民共创、充满创意与想象力的新时代。

扫码入群探讨更多前沿技术进展
市场生态合作:fuxi.mkt@service.netease.com
商务合作:fuxi@service.netease.com
合作电话:(0571)89852163转21951











