近日,国际知识发现与数据挖掘大会 (ACM SIGKDD Conference on Knowledge Discovery and Data Mining,简称 KDD)公布了论文接收结果:网易伏羲共有四篇论文中稿Research Track和Applied Data Science Track。这四篇论文的研究方向涉及可解释性、在线营销、组合优化、主动学习等多个领域的关键问题,为数据科学领域带来了新的亮点。

KDD 是数据科学领域历史最悠久、规模最大的国际顶级学术会议,也是中国计算机学会(CCF)推荐的A类国际学术会议。自成立以来,KDD聚焦于数据挖掘、知识发现和大数据分析等领域的最新研究及应用进展,涉及机器学习、人工智能、统计学、数据库技术、数据可视化等研究领域,吸引了大量来自世界各地的学术界、工业界专业人士参与。今年,KDD 2024会议Research Track共收到2046篇论文投稿,Applied Data Science Track共接收738篇投稿,接受率仅20%,网易伏羲凭借深厚的科研底蕴与前瞻的技术实力成功入选四篇论文。截至目前为止,网易伏羲已累计发表200余篇人工智能顶会论文。
以下为网易伏羲此次入选的论文概要:
一、《XRL-Bench: A Benchmark for Evaluating and Comparing Explainable Reinforcement Learning Techniques》
XRL-Bench: 评估和比较可解释强化学习技术的基准
关键词:可解释强化学习,可解释AI,Benchmark
涉及领域:Explainable RL,Explainable AI
论文链接:https://arxiv.org/abs/2402.12685
项目主页:https://github.com/fuxiAIlab/xrl-bench
随着强化学习(RL)在游戏AI、机器人技术及工业控制等领域的广泛应用,其决策过程的可解释性愈发成为关乎可靠性和透明度的关键议题,尤其在对智能系统决策合理性与安全性有着极高要求的实际场景中,强化学习模型的“黑箱”特性成为制约其广泛接纳与部署的一大瓶颈。为破解这一难题,网易伏羲群体智能组推出开源项目XRL-Bench,通过构建一个涵盖RL环境、状态解释器与评估器三大模块的标准化评估框架,为可解释强化学习(XRL)方法的研发与评估提供稳固支撑。XRL-Bench旨在搭建一个综合、开放且易于使用的平台,为游戏竞技机器人的决策过程提供清晰、可量化且可比较的解释,从而赋能全球科研人员与从业者更有效地研发、测试与对比各类XRL算法。
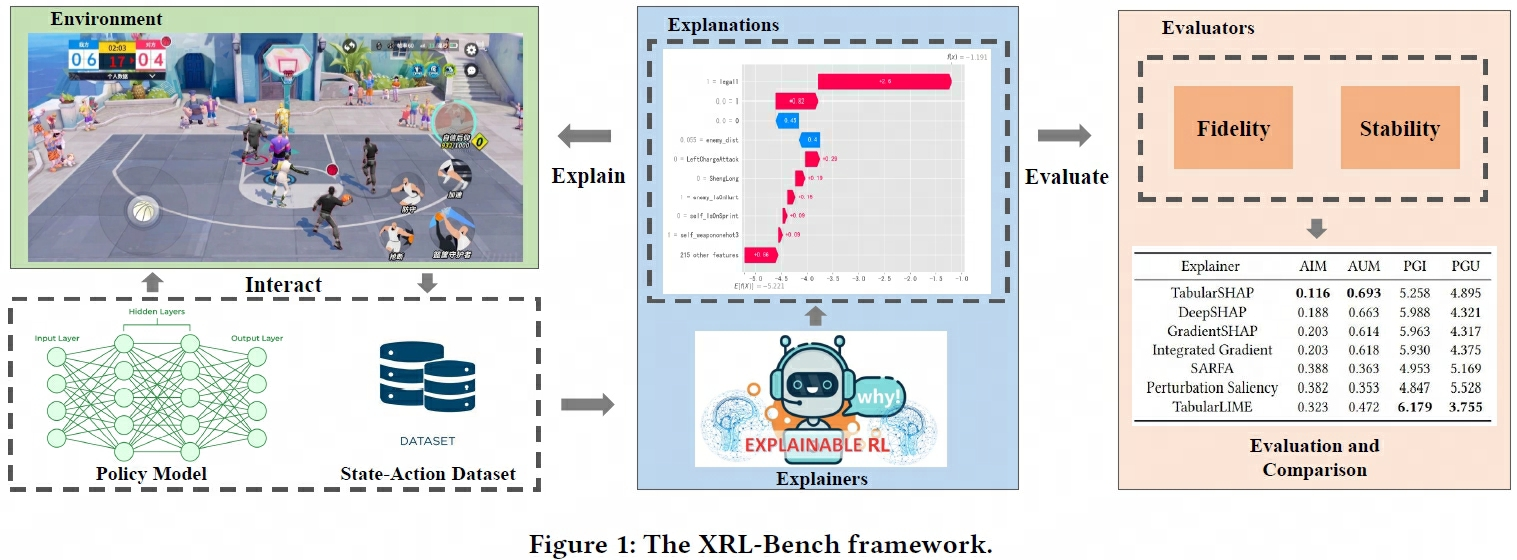
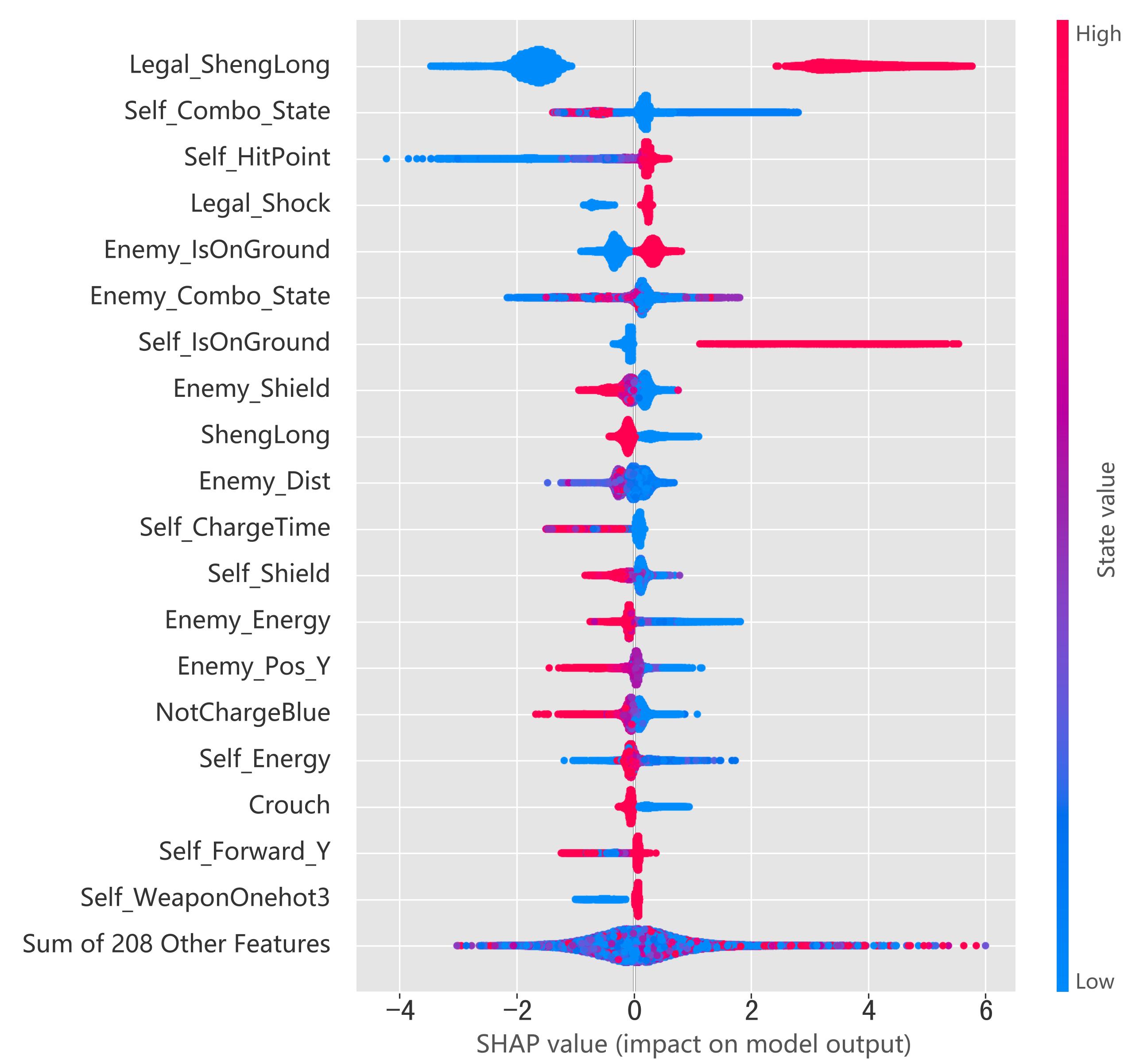
该框架包含游戏环境、解释器、评估器,支持表格和图像状态输入,覆盖《全明星街球派对》等六款游戏环境。借助DRL训练的智能体和数据集,XRL-Bench提供CSV和MDPDataset格式数据,以及深度神经网络直接解释难题的解决方案,如TabularSHAP。该方法通过集成树模型学习策略,并利用TreeSHAP为RL智能体的决策过程提供透明解释。XRL-Bench提供五项评估指标,包括保真度的AIM、AUM、PGI、PGU和稳定性的RIS,形成全面评估体系。该平台简化了环境配置、数据生成、解释器初始化到解释评估的流程,便于扩展使用。
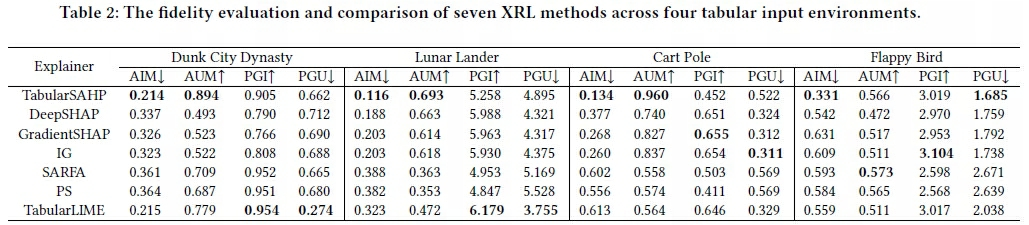
XRL-Bench已在《永劫无间》等网易游戏AI中应用,通过TabularSHAP分析,揭示了AI行为背后的关键因素,帮助开发者深入理解内部逻辑,提高诊断和开发效率。例如,在《永劫无间》中,TabularSHAP帮助找出AI机器人在执行连招时出现的中断问题,经排查是编程接口bug所致。修复后,AI成功掌握高级连招技巧。
作为一项里程碑式的开源项目,XRL-Bench不仅为全球研究者和开发者提供了统一的XRL方法测试平台,更彰显了网易伏羲在推动游戏竞技机器人可解释性技术进步上的领导力与创新精神。未来,XRL-Bench将持续拓展环境、解释方法与评估指标的覆盖范围,赋能更多AI机器人项目,助力游戏开发者高效诊断问题、优化策略,以及为玩家提供详实的AI行为解读。同时,网易伏羲将继续开发AI机器人可解释工具,构建客观的机器人水平和风格评价体系,推出AI教练战斗复盘报告功能,以科技力量持续缩短机器人开发周期,提升游戏AI的智能化水平与用户体验。
二、《MGMatch: Fast Matchmaking with Nonlinear Objective and Constraints via Multimodal Deep Graph Learning》
MGMatch:通过多模态深度图学习实现快速匹配,解决非线性目标和约束
关键词:游戏战斗匹配,非线性组合优化
涉及领域:Matchmaking, Neural Combinatorial Optimization
论文链接:https://openreview.net/attachment?id=MLErD6Hnwt&name=pdf
论文网站:https://openreview.net/forum?id=MLErD6Hnwt
作为在线游戏的核心问题,匹配是将玩家分配到多个团队,以最大化他们的游戏体验。随着游戏领域的迅猛发展,传统上将玩家体验简化为线性模型的做法已难以适应复杂的现实需求。相反,通过训练神经网络进行数据驱动的体验建模已成为主流趋势。然而,这一过程还需兼顾一系列复杂规则,用以保障匹配机制的稳定性和公平性,这些规则常通过逻辑运算符进行描述。因此,实际操作中,游戏匹配问题演变成了一项具有非线性目标、线性约束和逻辑约束的挑战性组合优化问题,在先前研究中鲜少得到深入探讨。
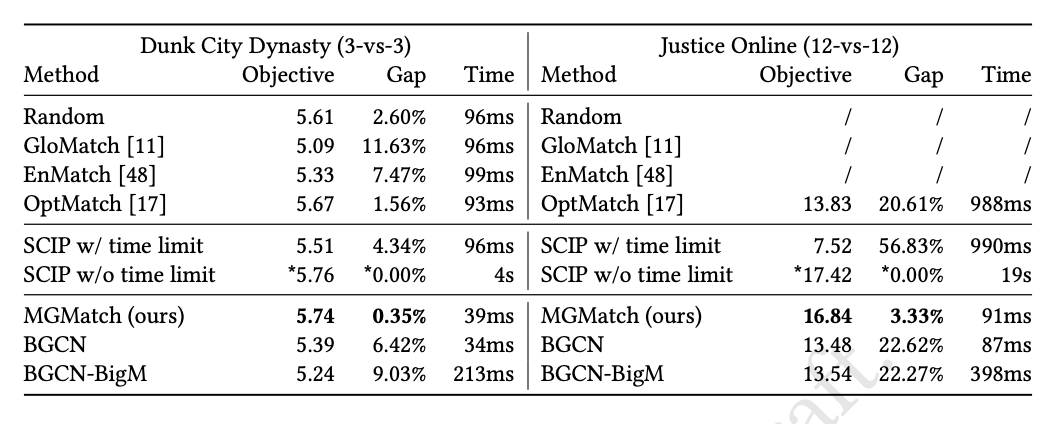
对此,我们创新性地提出了一种新颖的深度学习方法,旨在实现实时、高质量的匹配。首先,我们将问题转化为标准的混合整数规划(MIP)问题,通过对ReLU网络和逻辑约束进行线性化。接着,基于监督学习原理,我们设计并训练了一个多模态图学习架构,能够从实例数据中端到端地预测出最优解,并解决一个代理问题以有效地获得可行解。通过对真实行业数据集的评估,结果表明我们的方法能够在100毫秒内提供接近最优的解决方案。
三、《Temporal Uplift Modeling for Online Marketing》
突破在线个性化营销难题 —— 时序uplift模型(TPPUM)
关键词:在线营销,uplift模型
涉及领域:recommendation system, causal inference
论文链接:https://openreview.net/attachment?id=jJy9pWeRJT&name=pdf
论文网站:https://openreview.net/forum?id=jJy9pWeRJT
近年来,uplift模型,也称为个体处理效应(ITE)估计,在在线营销领域得到了广泛应用,例如通过提供一次性的优惠券或折扣来激励用户购买。然而,在涉及用户多次干预的复杂且更为现实的场景中,这类模型的应用仍然相对较少。这些场景带来的挑战包括处理随时间变化的混杂因素偏差、确定最佳干预时机以及在众多处理选项中进行选择。
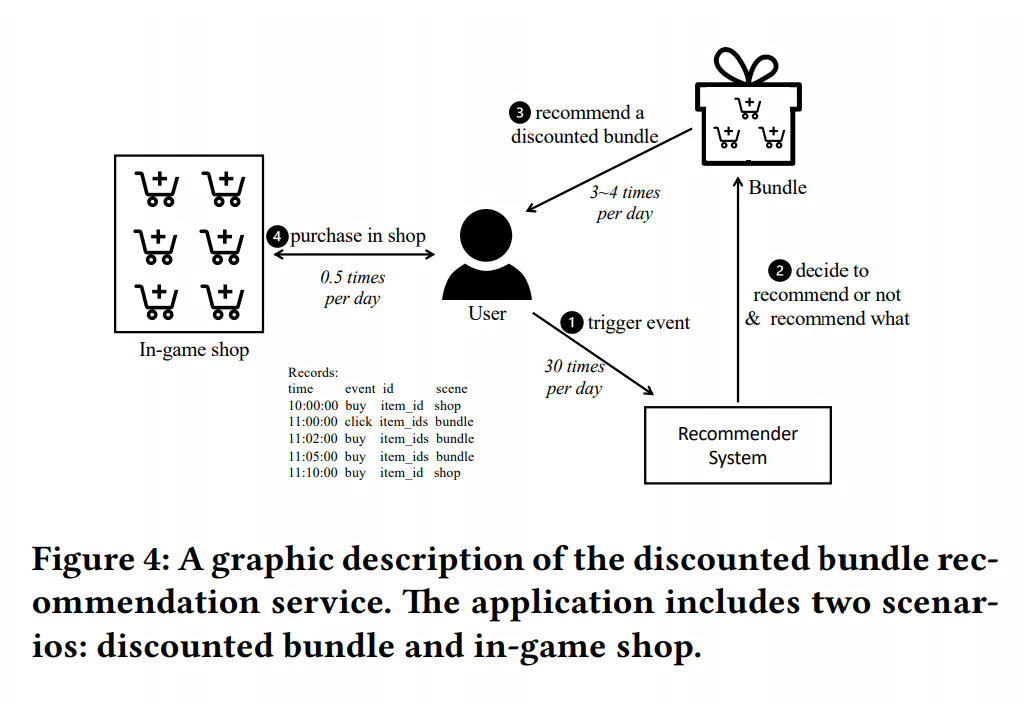
为了应对这些挑战,我们提出了一种基于时间点过程的提升模型(TPPUM)。该模型通过反事实分析和时间点过程,利用用户的时间事件序列来估计处理效应。在该模型中,营销行动被视为处理,用户购买被视为结果事件,处理如何改变未来生成结果事件的条件强度函数被视为提升。在涉及每天平均3到4次干预和数百个处理候选者的折扣捆绑推荐场景的在线实验中,我们的新方法明显提升了用户消费体验和应用的整体收入。这一结果证明了我们方法在处理复杂干预场景中的有效性和实用性。
四、《CoMAL: Contrastive Active Learning for Multi-Label Text Classification》
CoMAL:通过对比主动学习,实现多标签文本分类
关键词:对比学习,主动学习,多标签分类
涉及领域:Constrastive Learning, Active Learning, Multi-Label Text Classification
论文链接:https://openreview.net/pdf?id=njR3i99F0f
论文网站:https://openreview.net/forum?id=njR3i99F0f
现实场景中普遍存在多标签文本分类(MLTC)问题,即需要对给定文本赋予多个标签。由于MLTC问题的标注耗时耗力,主动学习成为提升效率和效果的一个主要路径。然而,在MLTC问题上的主动学习应用仍面临诸多挑战,例如如何构建合理的特征空间以实现不同语义标签下的数据分离,以及如何为整个标签空间设计出合理的采样策略标准。
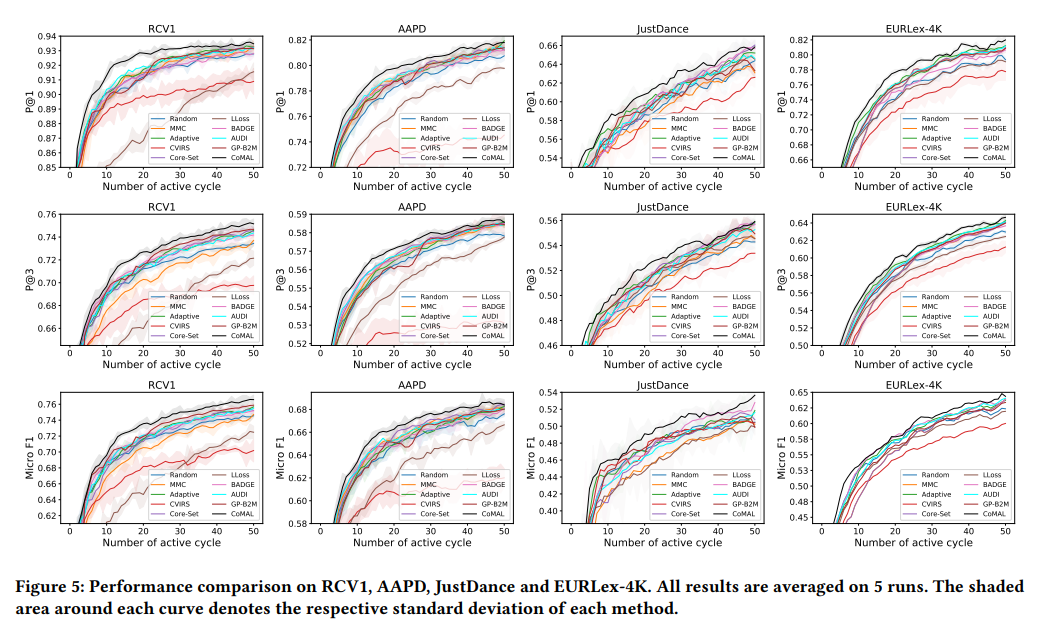
为了解决这些问题,我们提出了对比多标签主动学习框架(CoMAL)来实现更加高效的数据集构造方案。具体而言,我们首先通过对比解耦学习来获取多个标签的语义信息,从而获得更好的特征表示,接着采用混合标准来评估数据价值,包括基于相似度增强的标签基数不一致性以及正面倾向性的语义多样性得分。通过大量的实验验证,证明了CoMAL框架在主动学习策略上的有效性。我们相信,这一方案有望提升网易伏羲在多个业务算法模型中的数据闭环迭代效率和效果。
该论文由网易伏羲与浙江大学王皓波老师合作完成。
此次,网易伏羲论文成果入选KDD 2024,再度彰显了其前沿技术实力与领先技术地位,既是对网易伏羲持续钻研技术研发的赞誉,更是对其利用人工智能创新不断驱动产业升级实践的认可。
展望未来,网易伏羲将坚守技术初心与创新本源,从应用场景出发,继续深入探索各领域前沿问题,广泛共享人工智能科技成果,秉持“人机协作,万物有灵”的发展愿景,与各领域伙伴紧密合作,加速促进人工智能技术与实体经济的深度融合,为人工智能的应用落地贡献力量。











